0G 的去中心化 AI 操作系统能否真正推动 AI 在链上大规模运行?
背景
在 ChatGPT 和 文心一言 (ERNIE Bot) 等大语言模型的推动下,AI 领域正处于飞速发展之中。然而,AI 不仅仅是聊天机器人和生成式文本;它还包括从 AlphaGo 的围棋胜利到 MidJourney 等图像生成工具的一切。许多开发者追求的终极目标是通用人工智能,即 AGI (Artificial General Intelligence) —— 通俗地被称为能够像人类智能一样进行学习、感知、决策和执行复杂任务的 AI “智能体” (Agent)。
然而,AI 和 AI Agent 应用都是极度 数据密集型 的。它们依赖海量数据集进行训练和推理。传统上,这些数据在中心化基础设施上存储和处理。随着区块链的出现,一种被称为 DeAI (去中心化 AI) 的新方法应运而生。DeAI 尝试利用去中心化网络进行数据存储、共享和验证,以克服传统中心化 AI 方案的弊端。
0G Labs 在 DeAI 基础设施领域脱颖而出,旨在构建一个被称为 0G 的 去中心化 AI 操作系统。
什么是 0G Labs?
在传统计算中,操作系统 (OS) 负责管理硬件和软件资源 —— 比如 Microsoft Windows、Linux、macOS、iOS 或 Android。操作系统抽象了底层硬件的复杂性,使最终用户和开发者能够更轻松地与计算机交互。
以此类推,0G OS 渴望在 Web3 中发挥类似的作用:
- 管理 去中心化存储、计算和数据可用性。
- 简化 链上 AI 应用程序的部署。
为什么要分去中心化? 传统的 AI 系统在中心化的孤岛中存储和处理数据,引发了对数据透明度、用户隐私以及数据提供者公平报酬的担忧。0G 的方法使用去中心化存储、加密证明和开放激励模型来降低这些风险。
名称 “0G” 代表 “Zero Gravity”(零重力)。团队设想了一个数据交换和计算感觉“无重量”的环境 —— 从 AI 训练到推理再到数据可用性,一切都在链上无缝进行。
0G 基金会 于 2024 年 10 月正式成立,负责推动这一倡议。其使命是将 AI 变成一种公共物品 —— 一种人人可及、可验证且开放的资源。

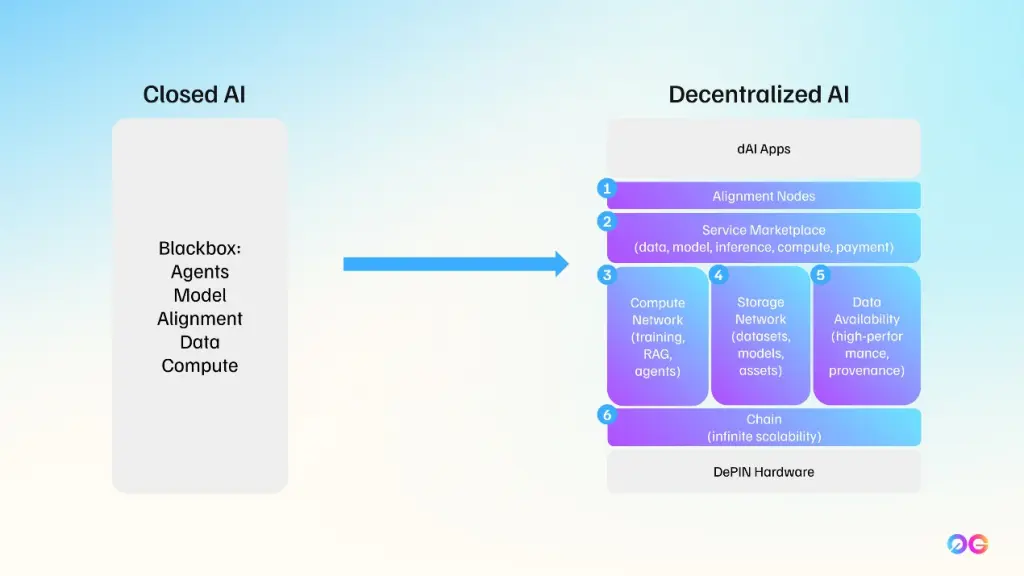
0G 操作系统的核心组件
从根本上说,0G 是一个专为支持链上 AI 应用而设计的模块化架构。它的 三大核心支柱 是:
- 0G Storage —— 一个去中心化存储网络。
- 0G DA (Data Availability) —— 一个确保数据完整性的专门数据可用性层。
- 0G Compute Network —— 用于 AI 推理(及未来的训练)的去中心化计算资源管理和结算系统。
这些支柱在名为 0G Chain 的 Layer1 网络 下协同工作,该网络负责共识和结算。
根据 0G 白皮书(“0G: Towards Data Availability 2.0”),0G Storage 和 0G DA 层都构建在 0G Chain 之上。开发者可以启动多个自定义的 PoS 共识网络,每个网络都作为 0G DA 和 0G Storage 框架的一部分运行。这种模块化方法意味着随着系统负载的增加,0G 可以动态添加新的验证者集或专门节点进行扩展。
0G Storage
0G Storage 是一个面向大规模数据的去中心化存储系统。它使用具有内置激励机制的分布式节点来存储用户数据。至关重要的是,它使用 纠删码 (Erasure Coding, EC) 将数据分割成 较小的、冗余的“数据块” (chunks),并将这些数据块分布在不同的存储节点上。如果某个节点发生故障,仍可以从冗余块中重建数据。
支持的数据类型
0G Storage 兼顾�了 结构化 和 非结构化 数据。
- 结构化数据 存储在 键值对 (KV) 层,适用于动态且频繁更新的信息(如数据库、协作文档等)。
- 非结构化数据 存储在 日志 (Log) 层,该层按时间顺序追加数据条目。这一层类似于针对大规模、仅追加工作负载而优化的文件系统。
通过在日志层之上堆叠 KV 层,0G Storage 可以服务于多样化的 AI 应用需求 —— 从存储大型模型权重(非结构化)到动态的用户数据或实时指标(结构化)。
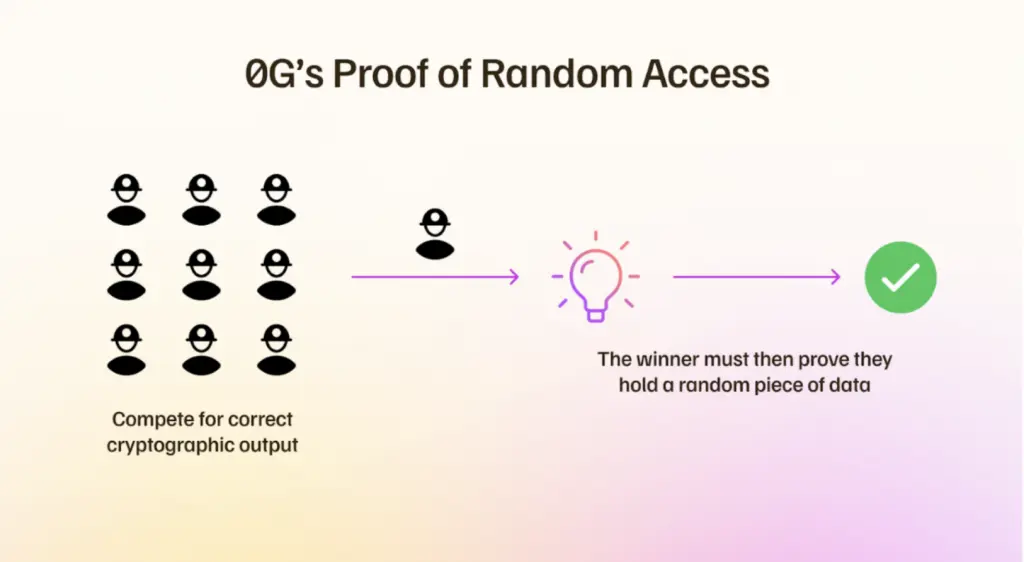
PoRA 共识
PoRA (Proof of Random Access,随机存取证明) 确保存储节点确实持有它们声称存储的数据块。其工作原理如下:
- 存储矿工会定期受到 挑战,要求生成他们存储的特定随机数据块的加密哈希。
- 他们必须通过生成一个有效的哈希(类似于类 PoW 的解题过程)来响应,该哈希源自其本地存储的数据副本。
为了公平竞争,系统将挖矿竞争限制在 8 TB 的分段内。大型矿工可以将其硬件细分为多个 8 TB 的分区,而小型矿工则在单个 8 TB 边界内竞争。
激励设计
0G Storage 中的数据被分为 8 GB 的“定价分段”。每个分段都有一个 捐赠池 和一个 奖励池。希望存储数据的用户支付 0G 代币 (ZG) 费用,这部分费用为节点奖励提供资金。
- 基础奖励: 当存储节点提交有效的 PoRA 证明时,它会获得该分段的即时区块奖励。
- 持续奖励: 随着时间的推移,捐赠池会将其中的一部分(目前每年约 4%)释放到奖励池中,激励节点 永久 存储数据。存储特定分段的节点越少,每个节点能赚取的份额就越大。
用户只需支付 一次 永久存储费用,但必须设置高于系统最小值的捐赠费。捐赠越高,矿工复制用户数据的可能性就越大。
版税机制: 0G Storage 还包含一种“版税”或“数据共享”机制。早期存储提供商会为每个数据块创建“版税记录”。如果新节点想要存储相同的数据块,原始节点可以共享它。当新节点稍后证明已存储(通过 PoRA)时,原始数据提供者将收到持续的版税。数据被复制得越广泛,早期提供者的总奖励就越高。
与 Filecoin 和 Arweave 的比较
相似之处:
- 三者都激励去中心化的数据存储。
- 0G Storage 和 Arweave 都旨在实现 永久 存储。
- 数据分块和冗余是标准方法。
关键区别:
- 原生集成: 0G Storage 不是一个独立��的区块链;它直接与 0G Chain 集成,主要支持以 AI 为核心的用例。
- 结构化数据: 0G 支持基于 KV 的结构化数据以及非结构化数据,这对于许多需要频繁读写访问的 AI 工作负载至关重要。
- 成本: 0G 声称永久存储费用为 10–11 美元/TB,据报道比 Arweave 更便宜。
- 性能焦点: 专为满足 AI 吞吐量需求而设计,而 Filecoin 或 Arweave 是更通用的去中心化存储网络。
0G DA (数据可用性层)
数据可用性 确保每个网络参与者都可以完全验证和检索交易数据。如果数据不完整或被扣留,区块链的信任假设就会崩溃。
在 0G 系统中,数据被分块并存储在链下。系统记录这些数据块的默克尔树根 (Merkle roots),而 DA 节点必须对这些块进行 采样,以确保它们与默克尔根和纠删码承诺相匹配。只有这样,数据才被视为“可用”并被追加到链的共识状态中。
DA 节点选择与激励
- DA 节点必须 质押 ZG 才能参与。
- 它们通过可验证随机函数 (VRF) 被随机分配到不同的 法定人数 (quorums) 中。
- 每个节点只验证数据的 子集。如果一个�法定人数中 2/3 的成员确认数据可用且正确,他们会签署一个证明,该证明被聚合后提交给 0G 共识网络。
- 奖励分配也通过定期采样进行。只有存储了随机采样数据块的节点才有资格获得该轮奖励。
与 Celestia 和 EigenLayer 的比较
0G DA 借鉴了 Celestia(数据可用性采样)和 EigenLayer(再质押)的思想,但旨在提供 更高的吞吐量。Celestia 的吞吐量目前在 10 MB/s 左右,区块时间约为 12 秒。同时,EigenDA 主要服务于 Layer2 解决方案,实现起来可能较为复杂。0G 设想实现 GB/s 级别的吞吐量,这更适合数据摄取量可能超过 50–100 GB/s 的大规模 AI 工作负载。
0G 计算网络
0G 计算网络 (0G Compute Network) 作为去中心化计算层。它的发展分为几个阶段:
- 第一阶段: 专注于 AI 推理的结算。
- 网络在去中心化市场中撮合“AI 模型买家”(用户)和计算提供商(卖家)。提供商在智能合约中注册其服务和价格。用户预存资金到合约中,消费服务,合约负责调解支付。
- 随着时间的推移,团队希望扩展到完整的 链上 AI 训练,尽管这更为复杂。
批处理: 提供商可以批量处理用户请求以减少链上开销,从而提高效率并降低成本。
0G Chain
0G Chain 是一个 Layer1 网络,作为 0G 模块化架构的基础。它支撑着:
- 0G Storage(通过智能合约)
- 0G DA(数据可用性证明)
- 0G Compute(结算机制)
根据官方文档,0G Chain 与 EVM 兼容,这使得需要高级数据存储、可用性或计算的 dApp 能够轻松集成。
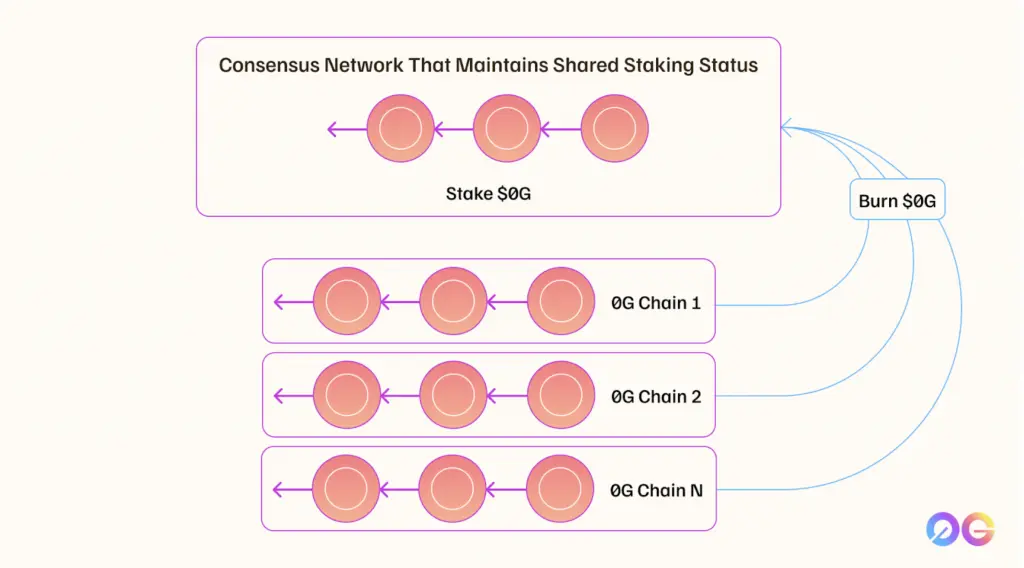
0G 共识网络
0G 的共识机制颇为独特。它不是一个单一的单体共识层,而是可以在 0G 下启动 多个独立的共识网络 来处理不同的工作负载。这些网络共享相同的质押基础:
- 共享质押 (Shared Staking): 验证者在以太坊上质押 ZG。如果验证者有不当行为,其在以太坊上质押的 ZG 可以被罚没 (slashed)。
- 可扩展性: 可以启动新的共识网络以实现水平扩展。
奖励机制: 当验证者在 0G 环境中完成区块最终确认时,他们会获得代币。然而,他们在 0G Chain 上赚取的代币在本地环境中会被 销毁,而验证者的以太坊账户中会 铸造 出等量的代币,从而确保流动性和安全性的单一来源。
0G 代币 (ZG)
ZG 是一种 ERC-20 代币,代表了 0G 经济的支柱。它通过以太坊上的 智能合约 进行铸造、销毁和流通。具体而言:
- 用户使用 ZG 支付存储、数据可用性和计算资源的费用。
- 矿工和验证者通过证明存储或验证数据赚取 ZG。
- 共享质押将安全模型关联回以太坊。
核心模块总结
0G OS 将存储、DA、计算和链这四个组件合并为一个相互连接的模块化堆栈。该系统的设计目标是 可扩展性,每一层都可以水平扩展。团队宣传其具有 “无限”吞吐量 的潜力,这对于大规模 AI 任务至关重要。
0G 生态系统
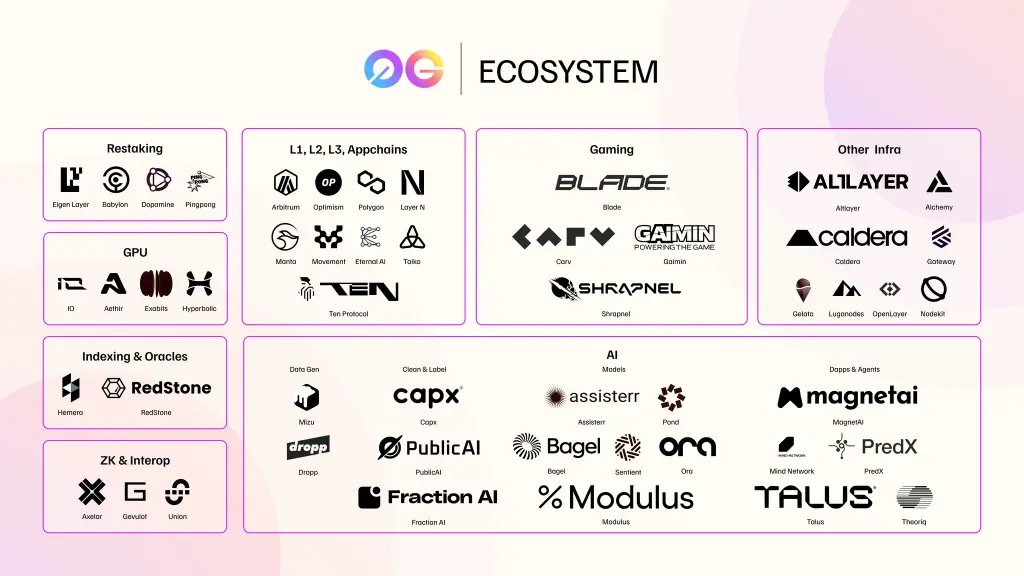
尽管 0G 生态系统 相对较新,但已经包含了关键的集成合作伙伴:
-
基础设施与工具:
- Union、Brevis、Gevulot 等 ZK 解决方案
- Axelar 等 跨链 解决方案
- EigenLayer、Babylon、PingPong 等 再质押 (Restaking) 协议
- IoNet、exaBits 等 去中心化 GPU 提供商
- Hemera、Redstone 等 预言机 (Oracle) 解决方案
- 以太坊 blob 数据的 索引 工具
-
使用 0G 进行数据存储和 DA 的项目:
- 用于 L2 / L3 集成的 Polygon、Optimism (OP)、Arbitrum、Manta
- 用于 Web3 基础设施的 Nodekit、AltLayer
- 用于链上游戏的 Blade Games、Shrapnel
供应侧
ZK 和 跨链 框架将 0G 连接到外部网络。再质押解决方案(如 EigenLayer、Babylon)加强了安全性,并可能吸引流动性。GPU 网络加速了纠删码(erasure coding)。预言机解决方案提供离线数据或参考 AI 模型定价。
需求侧
AI 代理 (AI Agents) 可以利用 0G 进行数据存储和推理。L2 和 L3 可以集成 0G 的 DA 以提高吞吐量。游戏 和其他需要稳健数据解决方案的 dApp 可以在 0G 上存储资产、日志或评分系统。一些项目已经与该项目建立了合作伙伴关系,这表明了早期的生态系统牵引力。
路线图与风险因素
0G 旨在使 AI 成为一种 公共事业 (public utility),任何人都可以访问和验证。团队渴望实现 GB/s 级别的 DA 吞吐量——这对于可能需要 50–100 GB/s 数据传输的实时 AI 训练至关重要。
联合创始人兼首席执行官 Michael Heinrich 表示,AI 的爆发式增长使得及时的迭代变得至关重要。AI 创新的速度很快;0G 自身的开发进度必须跟上。
潜在的权衡:
- 当前对 共享质押 (shared staking) 的依赖可能是一个中间方案。最终,0G 计划引入一个可水平扩展的共识层,该层可以增量增强(类似于启动新的 AWS 节点)。
- 市场竞争: 去中心化存储、数据可用性和计算领域存在许多专门的解决方案。0G 的全方位(all-in-one)方法必须保持竞争力。
- 采用与生态系统增长: 如果没有强大的开发者牵引力,所承诺的“无限吞吐量”仍将停留在理论阶段。
- 激励措施的可持续性: 节点的持续动力取决于真实的用户需求和平衡的代币经济。
结论
0G 尝试将去中心化存储、数据可用性和计算统一到支持链上 AI 的单个“操作系统”中。通过瞄准 GB/s 吞吐量,团队寻求突破目前阻碍大规模 AI 迁移到链上的性能瓶颈。如果成功,0G 可以通过提供 可扩展、集成且对开发者友好 的基础设施,显著加速 Web3 AI 浪潮。
尽管如此,仍有许多悬而未决的问题。“无限吞吐量”的可行性取决于 0G 的模块化共识和激励结构是否能够无缝扩展。外部因素——市场需求、节点正常运行时间、开发者采用率——也将决定 0G 的持久力。尽管如此,0G 解决 AI 数据瓶颈的方法是新颖且雄心勃勃的,预示着链上 AI 的一个充满希望的新范式。