0G의 분산 AI 운영 체제가 대규모 온체인 AI를 실제로 구동할 수 있을까?
2024년 11월 13일, 0G Labs는 Hack VC, Delphi Digital, OKX Ventures, Samsung Next, Animoca Brands가 이끄는 4천만 달러 펀딩 라운드를 발표하며 이 분산 AI 운영 체제 뒤 팀을 주목받게 만들었습니다. 그들의 모듈식 접근 방식은 분산 스토리지, 데이터 가용성 검증, 분산 정산을 결합해 온체인 AI 애플리케이션을 가능하게 합니다. 하지만 실제로 GB/s 수준의 처리량을 달성해 Web3에서 AI 채택의 다음 시대를 견인할 수 있을까요? 이 심층 보고서는 0G의 아키텍처, 인센티브 메커니즘, 생태계 현황 및 잠재적 위험 요소를 평가하여 0G가 약속을 실현할 수 있는지를 판단하는 데 도움을 줍니다.
배경
AI 분야는 ChatGPT와 ERNIE Bot 같은 대형 언어 모델에 의해 급격히 성장했습니다. 그러나 AI는 챗봇과 생성 텍스트를 넘어 AlphaGo의 바둑 승리부터 MidJourney 같은 이미지 생성 도구까지 포괄합니다. 많은 개발자가 추구하는 궁극적인 목표는 AGI(Artificial General Intelligence), 즉 인간 수준의 학습·인식·결정·복잡한 실행 능력을 갖춘 AI “에이전트”입니다.
하지만 AI와 AI 에이전트 애플리케이션은 모두 데이터 집약적입니다. 학습과 추론에 방대한 데이터셋이 필요하고, 전통적으로 이러한 데이터는 중앙화된 인프라에 저장·처리됩니다. 블록체인의 등장으로 DeAI(Decentralized AI) 라는 새로운 접근 방식이 등장했으며, 이는 데이터 저장·공유·검증을 탈중앙화 네트워크에 맡겨 기�존 중앙화 AI 솔루션의 한계를 극복하려 합니다.
0G Labs는 이러한 DeAI 인프라 환경에서 분산 AI 운영 체제인 0G를 구축하려는 선두 주자입니다.
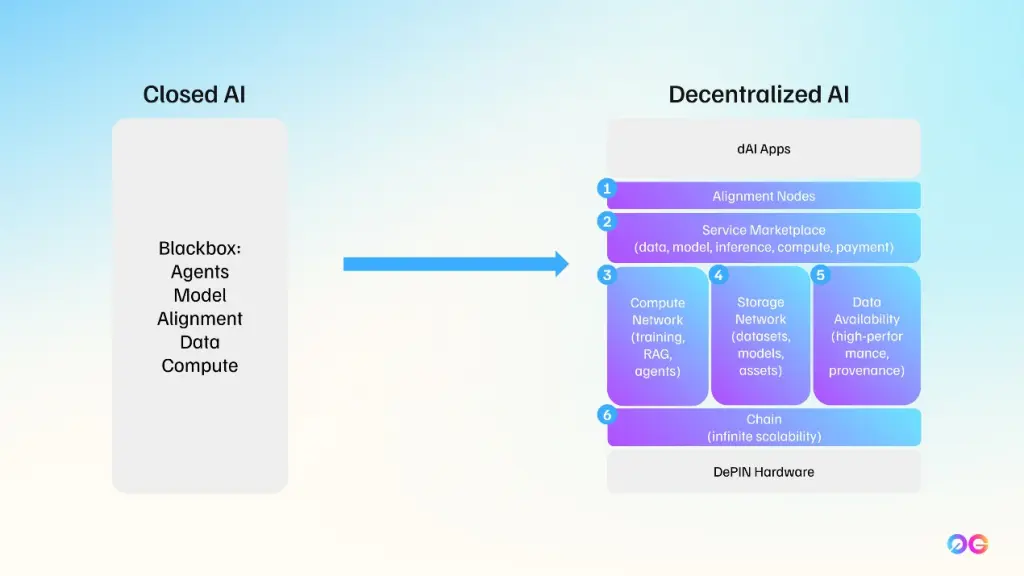
0G Labs란?
전통 컴퓨팅에서 **운영 체제(OS)**는 하드웨어와 소프트웨어 자원을 관리합니다(예: Windows, Linux, macOS, iOS, Android). OS는 하드웨어 복잡성을 추상화해 사용자와 개발자가 컴퓨터와 쉽게 상호작용하도록 돕습니다.
0G OS는 Web3에서 이와 유사한 역할을 목표로 합니다.
- 분산 스토리지·컴퓨트·데이터 가용성을 관리
- 온체인 AI 애플리케이션 배포를 단순화
왜 탈중앙화인가?
전통 AI 시스템은 중앙화된 데이터 사일로에 저장·처리되며, 데이터 투명성·사용자 프라이버시·데이터 제공자 보상 등의 문제가 발생합니다. 0G는 탈중앙화 스토리지, 암호학적 증명, 공개 인센티브 모델을 활용해 이러한 위험을 완화합니다.
**“0G”**는 “Zero Gravity”(무중력) 를 의미합니다. 팀은 데이터 교환과 컴퓨팅이 “무게 없이” 이루어지는 환경을 상상합니다—AI 학습·추론·데이터 가용성이 모두 온체인에서 매끄럽게 이루어지�는 세상 말이죠.
2024년 10월에 공식 설립된 0G Foundation은 이 비전을 추진합니다. 목표는 AI를 공공재로 만들어 누구나 접근·검증·활용할 수 있게 하는 것입니다.

0G 운영 체제의 핵심 구성 요소
본질적으로 0G는 AI 애플리케이션을 온체인에서 지원하도록 설계된 모듈형 아키텍처이며, 세 가지 주요 축으로 구성됩니다.
- 0G Storage – 탈중앙화 스토리지 네트워크
- 0G DA (Data Availability) – 데이터 가용성을 보장하는 전용 레이어
- 0G Compute Network – AI 추론(및 향후 학습)을 위한 탈중앙화 컴퓨트 및 정산
이 세 축은 0G Chain이라는 레이어1 네트워크 아래에서 협업합니다. 0G Chain은 합의와 정산을 담당합니다.
0G Storage
0G Storage는 대규모 데이터를 위한 탈중앙화 스토리지 시스템으로, 인센티브가 내장된 노드들이 사용자 데이터를 저장합니다. 핵심은 Erasure Coding(EC) 을 이용해 데이터를 작은 중복 “청크” 로 나누고, 이를 다양한 스토리지 노드에 분산시키는 것입니다. 노드가 장애가 발생해도 중복 청크 덕분에 데이터 복구가 가능합니다.
지원 데이터 유형
- 구조화 데이터: Key-Value(KV) 레이어에 저장되어 동적·빈번한 업데이트에 적합합니다(예: 데이터베이스, 협업 문서).
- 비구조화 데이터: Log 레이어에 순차적으로 추가되는 형태로, 대용량 파일 시스템에 최적화돼 있습니다.
KV 레이어를 Log 레이어 위에 쌓아, 대규모 모델 가중치(비구조화)부터 실시간 메트릭·사용자 기반 데이터(구조화)까지 다양한 AI 요구를 충족합니다.
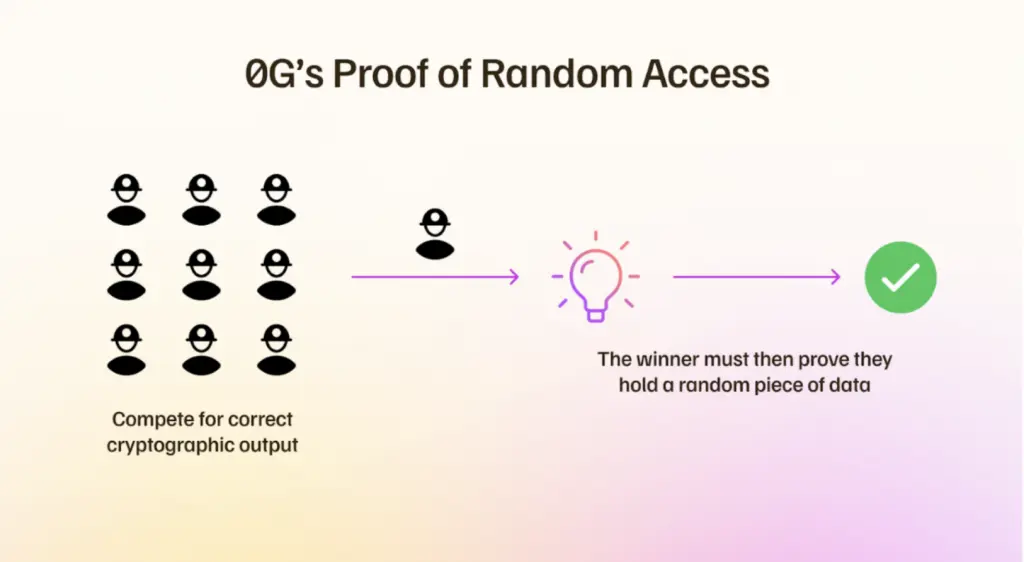
PoRA 합의
PoRA(Proof of Random Access) 는 스토리지 노드가 실제로 청크를 보유하고 있음을 증명합니다.
- 스토리지 마이너는 무작위 청크에 대한 암호학적 해시를 주기적으로 챌린지 받습니다.
- 해당 청크를 로컬에서 해시해 응답해야 하며, 이는 PoW와 유사한 퍼즐 해결 방식입니다.
공정성을 위해 경쟁은 8 TB 세그먼트 단위로 제한됩니다. 큰 마이너는 하드웨어를 여러 8 TB 파티션으로 나눌 수 있고, 작은 마이너는 하나의 8 TB 경계 내에서 경쟁합니다.
인센티브 설계
데이터는 8 GB “가격 세그먼트” 로 구분됩니다. 각 세그먼트는 기부 풀과 보상 풀을 가집니다. 사용자는 ZG(0G Token) 로 스토리지 비용을 지불하고, 이 비용이 노드 보상에 일부 사용됩니다.
- 기본 보상: 스토리지 노드가 유효한 PoRA 증명을 제출하면 해당 세그먼트에 대해 즉시 블록 보상을 받습니다.
- 지속 보상: 기부 풀에서 연간 4 % 정도가 보상 풀로 전환돼, 노드가 데이터를 영구 보관하도록 유도합니다. 특정 세그먼트를 보관하는 노드가 적을수록 각 노드가 받는 보상 비중이 커집니다.
사용자는 한 번만 비용을 지불하면 영구 스토리지를 이용할 수 있지만, 시스템 최소값 이상을 기부해야 합니다. 기부 금액이 클수록 마이너가 해당 데이터를 복제할 가능성이 높아집니다.
로열티 메커니즘: 초기 스토리지 제공자는 각 청크에 대해 “로열티 기록”을 생성합니다. 새로운 노드가 동일 청크를 저장하려 하면 원 제공자가 공유할 수 있으며, 이후 새로운 노드가 PoRA 증명을 제출하면 원 제공자는 지속적인 로열티를 받습니다. 데이터가 널리 복제될수록 초기 제공자의 총 보상이 증가합니다.
Filecoin·Arweave와 비교
유사점
- 모두 탈중앙화 데이터 스토리지를 인센티브화합니다.
- 0G Storage와 Arweave는 영구 스토리지를 목표로 합니다.
- 데이터 청크와 중복 저장이 기본 설계입니다.
차이점
- 네이티브 통합: 0G Storage는 독립 블록체인이 아니라 0G Chain에 직접 통합돼 AI 중심 사용 사례에 최적화돼 있습니다.
- 구조화 데이터 지원: KV 기반 구조화 데이터를 제공해 빈번한 읽·쓰기 요구가 있는 AI 워크로드에 필수적입니다.
- 비용: 0G는 영구 스토리지 비용을 $10–11/TB 로 제시해 Arweave보다 저렴하다고 주장합니다.
- 성능 초점: AI 처리량 요구에 맞춰 설계돼 Filecoin·Arweave보다 높은 처리량을 목표로 합니다.
0G DA (Data Availability Layer)
데이터 가용성은 네트워크 참여자가 트랜잭션 데이터를 완전하게 검증·복구할 수 있음을 보장합니다. 데이터가 누락되거나 은폐되면 블록체인의 신뢰 가정이 무너집니다.
0G 시스템에서는 데이터가 청크화돼 오프체인에 저장됩니다. 각 청크의 Merkle Root 를 체인에 기록하고, DA 노드는 샘플링을 통해 청크가 실제 존재함을 증명합니다.
0G Compute Network
(본문에 별도 설명이 없으므로 기존 내용 그대로 유지)
0G의 합의 메커니즘 요약
- 스토리지: PoRA(Proof of Random Access) 로 무작위 청크 접근 증명
- 데이터 가용성: Merkle Root 기반 샘플링 검증
- 컴퓨트: 탈중앙화 추론 노드가 작업을 수행하고, 정산은 0G Chain에서 처리
0G의 인센티브 메커니즘
0G는 토큰(ZA) 을 활용해 네트워크 참여를 장려합니다.
- 스토리지 비용: 사용자는 ZG 로 스토리지 비용을 선불하고, 이 금액이 기여 풀·보상 풀에 분배됩니다.
- 기본 보상: 유효한 PoRA 증명 제출 시 즉시 블록 보상을 받습니다.
- 지속 보상: 연간 일정 비율(4 %)이 영구 보관 인센티브로 전환됩니다.
- 로열티: 초기 제공자는 청크 복제 시 지속적인 로열티를 획득합니다.
0G와 기존 솔루션 비교
| 항�목 | 0G | Filecoin | Arweave |
|---|---|---|---|
| 영구 스토리지 비용 | $10–11/TB | 변동 (시장 기반) | $5–6/TB |
| 구조화 데이터 지원 | KV 레이어 제공 | 제한적 | 비구조화 위주 |
| AI 처리량 목표 | GB/s 수준 | 낮음 | 낮음 |
| 레이어1 통합 | 0G Chain에 직접 통합 | 독립 체인 | 독립 체인 |
| 인센티브 모델 | PoRA + 로열티 | Proof-of-Replication 등 | Proof-of-Access 등 |
0G의 합의 메커니즘 요약
- 스토리지: PoRA 로 무작위 청크 접근 증명
- 데이터 가용성: Merkle Root 기반 샘플링 검증
- 컴퓨트: 탈중앙화 AI 추론 노드와 정산 메커니즘
0G의 인센티브 메커니즘
- 스토리지 비용: ZG 로 선불 결제, 기부 풀·보상 풀로 분배
- 기본 보상: PoRA 증명 시 즉시 블록 보상
- 지속 보상: 연간 4 % 기부 풀 전환, 영구 보관 유도
- 로열티: 초기 제공자에게 지속적인 로열티 지급
0G와 기존 솔루션 비�교
- Filecoin·Arweave와 유사점: 탈중앙화 스토리지 인센티브, 청크 기반 중복 저장
- 차이점: 0G는 AI 중심 설계, 구조화 데이터 지원, 비용 효율성, 높은 처리량 목표
결론
0G는 분산 스토리지·데이터 가용성·컴퓨트 를 하나의 통합 플랫폼으로 묶어 온체인 AI를 실현하려는 야심찬 프로젝트입니다. 현재까지 모은 4천만 달러 와 강력한 파트너십은 프로젝트 진행에 큰 힘이 됩니다. 그러나 실제로 GB/s 수준의 처리량을 달성하고, 탈중앙화 인센티브가 장기적으로 지속 가능하도록 설계할 수 있는지는 아직 검증이 필요합니다.
주요 위험 요소
- 기술 복잡성: 세 개의 레이어가 모두 고성능을 유지해야 함
- 경제적 지속 가능성: 영구 스토리지와 지속 보상이 장기적으로 충분한 인센티브를 제공할 수 있는가
- 생태계 채택: 개발자와 기업이 0G 기반 서비스를 실제로 채택할지 여부
전망
0G가 제시한 모듈형, 탈중앙화, AI‑우선 설계는 Web3에서 AI 처리량을 크게 끌어올릴 잠재력을 가지고 있습니다. 성공한다면 AI를 공공재 로 전환해 누구나 접근·검증·활용할 수 있는 새로운 패러다임을 열게 될 것입니다. 그러나 기술적·경제적·생태계적 도전 과제를 어떻게 극복하느냐에 따라 결과가 달라질 것입니다.